pandas 入門 - pandasによるデータ処理の基礎
pandas は主に Excel のような2次元のテーブルを対象にしたライブラリです。Pythonで数値処理や統計処理、機械学習を行う際にnumpyなどと共によく利用されます。
目次
インストールとimport
pip install pandasインストールはpipを使って行います。pipを使ったことがない場合はPythonパッケージ管理に関するドキュメントを参照して下さい。
import pandas as pdpandasはpdとしてimportするのが慣習なのでpdとしてimportしましょう。ついでに他の数値ライブラリと一緒にimportしておきましょう。
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Jupyter notebookでグラフを出す場合
%matplotlib inlinepandasの基礎: DataFrame と Series
pandas の基本的なデータ構造に DataFrame と Serries があります。この2つが何を表すのかを始めに理解しましょう。
DataFrame
DataFrame が pandasのメインとなるデータ構造で二次元のテーブルを表します。図のような二次元のテーブルがDataFrameです。
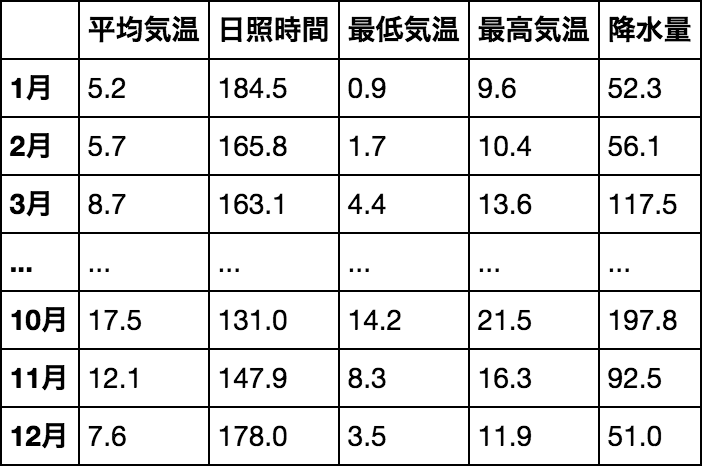
DataFrameは単なる二次元のlistではなく、各行・各列に対して"平均気温", "日照時間"や"1月", "2月"のような「ラベル」を付与することができます。Excelなどの一般的な2次元データのように横方向のデータが行(row)、縦方向のデータを列(column)です。
基本的には各列が"気温"や"降水量"などの特徴に対応し、各行が1つ1つのデータとするのが慣習です。この辺りもExcelなどと変わらないと思います。
Series
pandas のもう1つの重要なデータがSeriesです。Seriesは1次元の配列で、2次元テーブルの列(column), 行(row)に相当します。
Seriesも単なる1次元のlistではなく、各要素に「ラベル」を付与することができます。
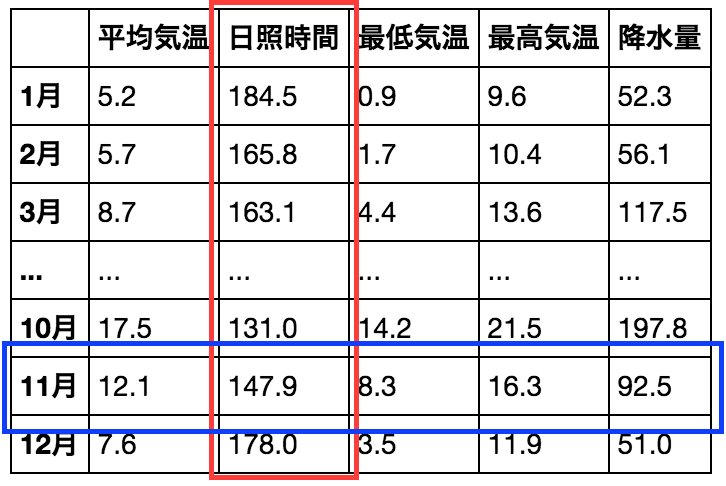
上のDataFrameから"日照時間"の列(赤い範囲)をSeriesとして取り出すと、

"11月"の行(青)をSeriesとして取り出すと

のようになります。
DataFrame と Series からデータを取り出す
まず pandas を初めて使った時に必要になり困惑するのが、要素の参照の仕方だと思います。pandasのDataFrameもPythonの他のデータと同じく[]で要素にアクセスすることができますが、[]のルールが不規則なのでルールを理解しておく必要があります。
DataFrameと[]
DataFrameに対して、df[key]のようにアクセスするとDataFrameはラベルがkeyの列(column)をSeriesとして返します。
多くのライブラリでは行列のの行, 列の要素にはX[i][j]のようにアクセスするのでX[i]は普通は行(横方向の1行)を返しますが、pandasは列を返すので注意が必要です。
次はsliceです。DataFrameに対して df[begin:end]のようにsliceでアクセスするとDataFrameは今度は行(row)のsliceを返します。
begin, endは行のラベルではなく行のオフセット(先頭からの位置)を渡します。
単にdf[key]としたときはkeyは列を指定するものであるにもかかわらず、df[begin,end]としたときはbegin, endは行を指定するのです。
このようにDataFrameに対する[]によるアクセスのルールはかなり不規則なので注意が必要です。
DataFrameのアクセス方法を表にまとめておきます。
| Operation | Syntax | Result |
|---|---|---|
| Select column | df[col] | Series |
| Select row by label | df.loc[label] | Series |
| Select row by integer location | df.iloc[loc] | Series |
| Slice rows | df[5:10] | DataFrame |
| Select rows by boolean vector | df[bool_vec] | DataFrame |
Seriesと[]
Seriesはdictのようにラベルで要素にアクセスすることも、listのように位置で要素にアクセスすることも可能です。
series[key]とすると、keyに一致するラベルが存在する場合にはdictのようにkeyにラベルが一致する要素が返されます。keyがラベルに一致せずintであるときにはlistのようにseries[index]はindex番目の要素を返します。
スライスを使った場合には、listと同じように振る舞います。series[1:3]は 1 <= index < 3の範囲の要素を含む長さ2のSeriesを返します。
DataFrame/Seriesの作り方
Series
まずはSeriesから作ります。Seriesはlistなどのiterableなデータから作ることができます。Seriesにもう1つiterableを渡すとラベルとして使われます。またdictを渡した場合は、dictのkeyがラベル,valueが値のSeriesが作られます。
series = pd.Series(data, index)pandasのドキュメントによると、二番目の引数indexは名前付き引数で呼び出すのが慣習のようです。
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])DataFrame
DataFrameは複数のSeriesから作成します。DataFrameに{column名: Series]のdictを渡すことでDataFrameを作成できます。
df = pd.DataFrame({'one' : pd.Series(np.random.randn(3), index=['a', 'b', 'c']),
'two' : pd.Series(np.random.randn(4), index=['a', 'b', 'c', 'd']),
'three' : pd.Series(np.random.randn(3), index=['b', 'c', 'd'])})columnにラベルをつける必要なければ、二次元の配列(list)やnumpyのndarrayから作ることもできます。
import pandas as pd
display(pd.DataFrame({'a': [1,2,3]}))
print 'From 2D list'
display(pd.DataFrame([[1, 2, 3], ['a', 'b', 'c'], [4.5, 6.7, 8.9]]))
print 'From numpy ndarray'
display(pd.DataFrame(np.eye(4)))よく使う機能
pandasのよく使う処理を簡単にいくつか書いておきます。pandasのAPIの一覧はすぐに参照できるようにブックマークしておくとよいです。
describe(): 各行の統計情報を表示
DataFrameのメソッドdescribe()を呼び出すと、2次元テーブルの各columnの統計情報の入った新しいDataFrameが返されます。DataFrameの中のデータの統計情報をぱっと確認したい時に便利です。得られる統計情報は要素数、最大値、最小値、平均などです。
df.describe()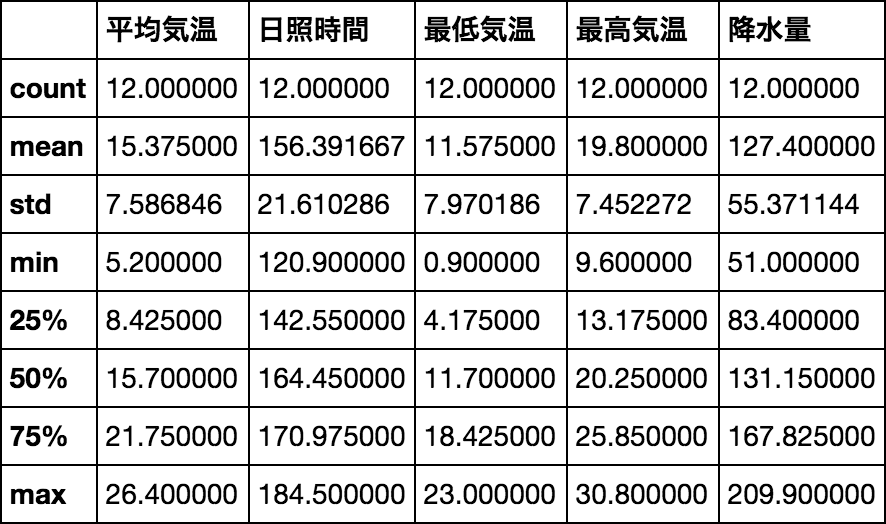
これらの統計情報は、df.count(要素数), df.mean(平均), df.std(標準偏差), df.max(最大値), df.min(最小値), df.var(分散)などで個別にも求められます。これらのメソッドは列(column)名をイ ンデックスとするSeriesを返します。
また、Seriesにもdescribe()があり1次元データの統計情報の入ったSeriesが返されますし、count, mean, stdなどで個別に値を求めることももちろん可能です。
df.mean()['平均気温'] == df['平均気温'].mean() # TrueDataFrame.corr(): 行と行の相関係数を表示
ランダムにシャッフルする
DataFrameにはreindexというメソッドがあって、行(row)のラベルの配列を与えると、そのラベルの順に行を並び替えたDataFrameが作られます。
# 1行目が'4月'のデータ, 2行目が'1月'のデータのDataFrame
df.reindex(['4月', '1月'])そのためreindexにrowのラベルをランダムに並べ替えたものを渡せばDataFrameの行をランダムに並び替えたDataFrameを作ることができます。
行のラベルの一覧は属性df.indexから取得できます。配列の並び替えをnumpy.random.permutationで行うと以下のようになります。
# DataFrameのrowをランダムにシャッフル
df.reindex(np.random.permutation(df.index))ランダムサンプリング
pandasのDataFrameから要素を幾つかランダムサンプリングしたい場合には、DataFrame.sampleを使用します。
df.sample(n=100)引数weightsを使うと特定の列を重みとして、重み付きランダムサンプリングを行うこともできます。
df.sample(n=100, weights='occurence')図として表示
よく使うようなグラフをmathplotlibを使って表示する機能がpandasには用意されています。 DataFrameのグラフ描画のメソッドはdf.plot.*に用意されています。 Jupyter notebookから使う場合は、グラフがinlineで表示されるように
%matplotlib inlineをnotebookの先頭で実行しておくことをおすすめします。
ヒストグラム
hist()メソッドで各columnのヒストグラムが表示されます。第一引数にcolumn名のリストを渡すと、ヒストグラムを表示する列を指定することができます。
df.hist()散布図
scatterを使うとx軸とy軸に使うcolumnを指定して散布図を表示できます。2つの列の間の相関を可視化する際に便利です。
df.scatter('x_column', 'y_column')